Searching available community pharmacies for #COVID vaccinations in Northern Ireland using C#

In northern Ireland, the over 40s should now go through the community pharmacy network to determine what pharmacies are administering the vaccine.
There is a useful web interface here: http://www.healthandcareni.net/pharmacy_rota/Covid_Vaccination_Pharmacies.html that allows you search for nearby pharmacies, but the process is quite frustrating, in that you have to click on 10-20 different pharmacies, before you find one that has slots available.
This tool allows you to search most of the the Northern Ireland pharmacy network in one go, to check for vacancies.
It’s available open source here: https://github.com/infiniteloopltd/NiCovid and I do welcome anyone to adapt this tool to something more user friendly.
It uses the SimplyBook booking system, which is used by most smaller pharmacies in northern ireland. Larger operations like boots use their own system, so this doesn’t cover other booking systems.
Technically, it extracts the list of pharmacies using the Simplybook service, and obtains a CRSF token from each site, once obtained, it makes a request to first check for services then for available days.
The date range is hardcoded, but it searches up to august 8th, I’m sure this can be changed easily.
Hope this helps someone!
Using the Google search #API in C#

If you are looking to automate some SEO / SERP processing in Google, it’s not long before you look to see how to automate the Google search API, and in this case, I’m using C#
Don’t even attempt to screen-scrape google, they will spot very quickly, and you’ll have wasted time doing HTML parsing for nothing, use the official API.
Now, the official API has one huge caveat, it is only useful for searching within a set number of specified sites. This means you can’t use it to determine, is my website in position #1 for keyword “Y”, but it can be used to check what pages of your site, or a competitor’s site are indexed.
This caveat rules out 99% of standard use cases, so feel free to close the page now, if it rules out your case. – Although I have seen that it is possible to include an entire Top Level Domain in the Custom search engine, like “*.es” (spain)
So, step 1 is to create a custom search engine, you do this from https://cse.google.com, and when it is created, copy the “cx” parameter, you will need this later
Step 2, go to https://developers.google.com/custom-search/v1/introduction/?apix=true and then press “Get A Key”, you’ll need this in step 3
Step 3, build up a URL as follows;
https://customsearch.googleapis.com/customsearch/v1?cx=…&key=…&q=….&start=0
Where cx and key are from step 1 and 2 above respectively.
Q is the search query
Start is a number from 0 to 90 Which represents the start position in the search results. You cannot return more than 100 results using this API.
To request, you just use some code like this
var apiUrl =
"https://customsearch.googleapis.com/customsearch/v1?cx=....&key=...&q=" +
searchTerm + "&start=" + start;
var response = http.Request(apiUrl);
var jResponse = JObject.Parse(response);And hopefully that helps someone!
#ZIP file decompression from first principles in C#

TL;DR; here is the Github repo: https://github.com/infiniteloopltd/Zip
First off, if you’re just looking to unzip a zip file, please stop reading, and look at System.IO.Compression instead, however, if you want to write some code in C# to repair a damaged Zip file, or to find a performant way to decompress one file out of a larger zip file, then perhaps this approach may be useful.
So, from Wikipedia, you can get the header format for a Zip file; which repeats for every zip entry (compressed file)
| Offset | Bytes | Description[31] |
|---|---|---|
| 0 | 4 | Local file header signature = 0x04034b50 (PK♥♦ or “PK\3\4”) |
| 4 | 2 | Version needed to extract (minimum) |
| 6 | 2 | General purpose bit flag |
| 8 | 2 | Compression method; e.g. none = 0, DEFLATE = 8 (or “\0x08\0x00”) |
| 10 | 2 | File last modification time |
| 12 | 2 | File last modification date |
| 14 | 4 | CRC-32 of uncompressed data |
| 18 | 4 | Compressed size (or 0xffffffff for ZIP64) |
| 22 | 4 | Uncompressed size (or 0xffffffff for ZIP64) |
| 26 | 2 | File name length (n) |
| 28 | 2 | Extra field length (m) |
| 30 | n | File name |
| 30+n | m | Extra field |
I only wanted a few fields out of these, so I wrote code to extract them as follows;
eader = BitConverter.ToInt32(zipData.Skip(offset).Take(4).ToArray());
if (header != 0x04034b50)
{
IsValid = false;
return; // Zip header invalid
}
GeneralPurposeBitFlag = BitConverter.ToInt16(zipData.Skip(offset + 6).Take(2).ToArray());
var compressionMethod = BitConverter.ToInt16(zipData.Skip(offset + 8).Take(2).ToArray());
CompressionMethod = (CompressionMethodEnum) compressionMethod;
CompressedDataSize = BitConverter.ToInt32(zipData.Skip(offset + 18).Take(4).ToArray());
UncompressedDataSize = BitConverter.ToInt32(zipData.Skip(offset + 22).Take(4).ToArray());
CRC = BitConverter.ToInt32(zipData.Skip(offset + 14).Take(4).ToArray());
var fileNameLength = BitConverter.ToInt16(zipData.Skip(offset + 26).Take(2).ToArray());
FileName = Encoding.UTF8.GetString(zipData.Skip(offset + 30).Take(fileNameLength).ToArray());
var extraFieldLength = BitConverter.ToInt16(zipData.Skip(offset + 28).Take(2).ToArray());
ExtraField = zipData.Skip(offset + 30 + fileNameLength).Take(extraFieldLength).ToArray();
var dataStartIndex = offset + 30 + fileNameLength + extraFieldLength;
var bCompressed = zipData.Skip(dataStartIndex).Take(CompressedDataSize).ToArray();
Decompressed = CompressionMethod == CompressionMethodEnum.None ? bCompressed : Deflate(bCompressed);
NextOffset = dataStartIndex + CompressedDataSize;This rather dense piece of code extracts relevant data from the zip entry header. It also determines if the zip entry is compressed, or left as-is, because with a very small file, then compression can actually increase the file size.
public enum CompressionMethodEnum
{
None = 0,
Deflate = 8
}This is the enum I used, 0 for no compression, and 8 for deflate.
Now, if the zip entry is actually compressed, then you really have to revert to some code in .NET to decompress it:
private static byte[] Deflate(byte[] rawData)
{
var memCompress = new MemoryStream(rawData);
Stream csStream = new DeflateStream(memCompress, CompressionMode.Decompress);
var msDecompress = new MemoryStream();
csStream.CopyTo(msDecompress);
var bDecompressed = msDecompress.ToArray();
return bDecompressed;
}I would really love if someone could implement this from first principles also, but the process is very very complicated, and it just fried my head trying to understand it.
So, with this in place, here is the loop I used to extract every file in the archive;
static void Main(string[] args)
{
var file = "hello3.zip";
var bFile = File.ReadAllBytes(file);
var nextOffset = 0;
do
{
var entry = new ZipEntry(bFile, nextOffset);
if (!entry.IsValid) break;
var content = Encoding.UTF8.GetString(entry.Decompressed);
Console.WriteLine(entry.FileName);
Console.WriteLine(content);
nextOffset = entry.NextOffset;
} while (true);
}So, you could perhaps use this code to try to repair a corrupt zip file, or maybe optimize the extraction, so you extract on certain data from a large zip – or whatever.
High performance extraction of unstructured text from a #PDF in C#

There are a myriad of tools that allow the extraction of text from a PDF, and this is code is not meant as a replacement for them, it was a specific case where I was looking to extract text from a PDF as fast as possible without worrying about the structure of the document. I.e. to very quickly answer the question “on what pages does the text “X” appear?”
In my specific case, performance was of paramount importance, knowing the layout of the page was unimportant.
The Github repo is here: https://github.com/infiniteloopltd/PdfToTextCSharp
And the performance was 10x faster than iText, parsing a 270 page PDF in 0.735 seconds.
It’s also a very interesting look at how one could go about creating a PDF reader from first principles, so without further ado, let’s take a look at a PDF, when opened in a text editor:
%PDF-1.7
%âãÏÓ
7 0 obj
<<
/Contents [ 8 0 R ]
/Parent 5 0 R
/Resources 6 0 R
/Type /Page
>>
endobj
6 0 obj
<<
/Font <<
/ttf0 11 0 R
/ttf1 17 0 R
>>
/ProcSet 21 0 R
>>
endobj
8 0 obj
<<
/Filter [ /FlateDecode ]
/Length 1492
>>
stream
..... BINARY DATA ...
endstreamWhat is interesting here, is that the page data is encoded in the “BINARY DATA” which is enclosed between the stream and endstream markers
This binary data can be decompressed using the Deflate method. There are other compression schemes used in PDF, and they can even be chained, but that goes beyond the scope of this tool.
Here is the code to uncompress deflated binary data;
private static string Decompress(byte[] input)
{
var cutInput = new byte[input.Length - 2];
Array.Copy(input, 2, cutInput, 0, cutInput.Length);
var stream = new MemoryStream();
using (var compressStream = new MemoryStream(cutInput))
using (var deflateStream = new DeflateStream(compressStream, CompressionMode.Decompress))
deflateStream.CopyTo(stream);
return Encoding.Default.GetString(stream.ToArray());
}So, I read through the PDF document, looking for markers of “stream” and “endstream”, and when found, I would snip out the binary data, deflate it to reveal this text;
/DeviceRGB cs
/DeviceRGB CS
q
1 0 0 1 0 792 cm
18 -18 901.05 -756 re W n
1.5 w
0 0 0 SC
32.05 -271.6 m
685.25 -271.6 l
S
32.05 -235.6 m
685.25 -235.6 l
S
1 w
32.05 -723.9 m
685.25 -723.9 l
S
BT
1 0 0 1 636 -743.7 Tm
0 0 0 sc
0 Tr
/ttf0 9 Tf
(270)Tj
-510 0.1 Td
0 Tr
(08-Apr-2021)TjMost of this text is relating to the layout and appearance of the page, and is once again, beyond the scope of the tool. I wanted to extract the text which is represented like (…)Tj , which I extracted using a regex as follows;
const string strContentRegex = @"\((?<Content>.*?)\)Tj";
UnstructuredContent = Regex.Matches(RawContent, strContentRegex)
.Select(m => m.Groups["Content"].Value)
.ToList();Once this was done, I could then write a Find function, that could find which pages a given string of text appeared;
public List<FastPDFPage> Find(string text)
{
return Pages
.Where(p => p.UnstructuredContent
.Any(c => string.Equals(c, text, StringComparison.OrdinalIgnoreCase)))
.ToList();
}And, in performance tests, this consistently performed at 0.735 seconds to scan 270 pages, much faster than iText, and a order of magnitude faster than PDF Miner for Python.
Search #Skype users via an #API, by name or email address

Skype has been around since 2003 and has over 660 million registered users. This is an API wrapper that allows access to the user search facility of the consumer version of skype (i.e. not Skype4business), via a simple interface that allows searching via email address or name
To learn more – go to https://rapidapi.com/infiniteloop/api/skype-graph
This API takes a single parameter, which can be either a name “Robert Smith”, or an email address “robert.smith@hotmail.com“
The response will be in JSON, following a format similar to this;
{
"requestId": "689067",
"results": [
{
"nodeProfileData": {
"skypeId": "bobbys88881",
"name": "Rob Smith",
"avatarUrl": "https://api.skype.com/users/bobbys88881/profile/avatar",
"country": "Ireland",
"countryCode": "ie",
"contactType": "Skype4Consumer",
"avatarImageUrl": "https://avatar.skype.com/v1/avatars/bobbys88881/public"
}
}
]
}
Above is a sample search for “robert.smith@hotmail.com”
Vehicle licence plate #API available in #CostaRica

Costa Rica is a central American country with a population of just over 5 million, and half of all households in Costa Rica own at least one vehicle. The number of cars in Costa Rica has more than doubled since 2006 to an automotive park of 1,794,658 vehicles registered up to Feb. 2018. 1,166,042 (65%) corresponds to automotive vehicles; 589,037 motorcycles (33%), 20,918 Micro Buses (1%) and 9,661 Buses (0.5%). The average age of a Costa Rican car is 16 years with 2003 models.
As of today, we have launched an API that allows users search for a vehicle registered in Costa Rica using it’s license plate (like BFH467 in the photo above), via the website http://www.placa.co.cr/
Car registration plates in Costa Rica use the /CheckCostaRica API endpoint and return the following information:
- Make / Model
- Age
- Wheelplan
- Engine size
- Fuel
- Representative image
Sample Registration Number:
706854
Sample Json:
{
“Description”: “DAIHATSU TERIOS”,
“CarMake”: {
“CurrentTextValue”: “DAIHATSU”
},
“CarModel”: {
“CurrentTextValue”: “TERIOS”
},
“MakeDescription”: {
“CurrentTextValue”: “DAIHATSU”
},
“ModelDescription”: {
“CurrentTextValue”: “TERIOS”
},
“EngineSize”: {
“CurrentTextValue”: “1500”
},
“RegistrationYear”: “2016”,
“Body”: “TODO TERRENO 4 PUERTAS”,
“Transmission”: “MANUAL”,
“Fuel”: “GASOLINA”,
“Cabin”: “CABINA SENCILLA”,
“WheelPlan”: “4X4”,
“ImageUrl”: “http://www.placa.co.cr/image.aspx/@REFJSEFUU1UgVEVSSU9T”
}
Upgrading #Cordova apps from #UIWebView to #WKWebView

Cordova hybrid iOS apps are based on the idea of wrapping a web application in a UIWebView in order to serve it as an app resembling a native iOS app. Apple has informed all iOS developers that UIWebView will be deprecated, and that new, or updated apps must use WKWebView instead. The idea that UIWebView could bypass fundamental restrictions that Web users are used to, is certainly problematic, and it’s not surprising that Apple has taken this move.
However, if you’ve got a Cordova based app, and need to make an upgrade, then perhaps you may need to take cognisance of these new limitations, and the upgrade path.
So, first off, to do the basic upgrade, you need to run the following command
cordova plugins add cordova-plugin-wkwebview-engineThen Make a modification to config.xml as follows;
<platform name="ios">
<preference name="WKWebViewOnly" value="true" />
<feature name="CDVWKWebViewEngine">
<param name="ios-package" value="CDVWKWebViewEngine" />
</feature>
<preference name="CordovaWebViewEngine" value="CDVWKWebViewEngine" />
</platform>Then rebuild the app using
cordova build iosThat’s the basic upgrade path, but let’s dive deeper. One of the abilities of UIWebView was that you could make cross-origin requests without any restrictions. This is no longer possible in WKWebView, so you need to make sure that your AJAX requests are CORS compliant.
Assuming the API you are connecting to is not CORS enabled, and you have no direct control over it to make it CORS enabled, you will need to use a CORS proxy. One of the easiest ways to do this is via an API gateway using AWS.
Log in to AWS, and go to API Gateway. Press “Create API”, then “Build” beside HTTP API, then Add Integration -> HTTP. Set the URL endpoint to the root domain of the destination API that you are trying to call. Give the API a name and press “Next” Set Resource path to $default and press next. Press Next again, then Create.
Once created, click on the API, and press CORS on the left hand side. Press Configure. In Access-Control-Allow-Origin type * and press add. Do the same for Access-Control-Allow-Headers and Access-Control-Expose-Headers. For Access-Control-Allow-Methods select each method in turn, and press Add. Finally, Press Save.
You will now have an CORS-Enabled API endpoint, like https://xxxxxxx.execute-api.yyyyyyyyy.amazonaws.com that you can use to call the target API endpoint.
Then update your app source code, to change the domain to point at the AWS domain rather than the target API.
Before you compile, there is one last step; you have to add the following plugin:
cordova plugin add https://github.com/TheMattRay/cordova-plugin-wkwebviewxhrfixWhat this does, is to set the origin header correctly within Cordova WKWebView, such that CORS will see it as a non-null origin, and will actually work.
Now, test your app, and hopefully you can now re-submit updates without apple complaining.
Greek vehicle lookup #API now generally available.
Greece has a population of 10.72 million, and a 5.28 million passenger cars which is a 49% car ownership rate, which is quite average for an EU country. Based on Eurostat data from 2018, graph below.
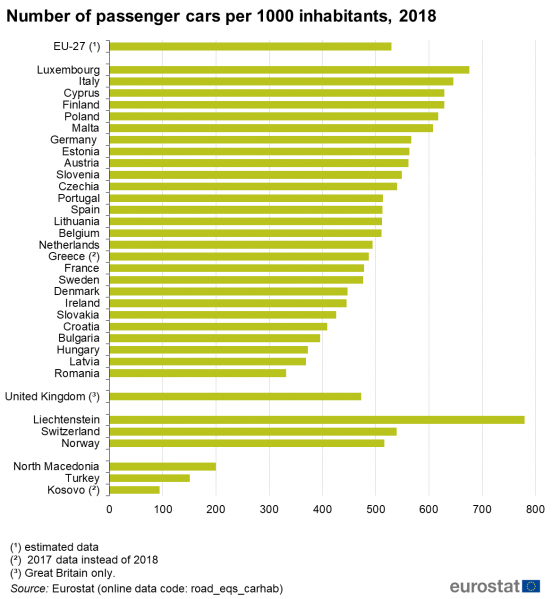
Today, we’ve launched our Greek API on the domain πινακιδα.gr which means “License plate” in Greek. The API endpoint is available at http://www.πινακιδα.gr/api/reg.asmx?op=CheckGreece
Car registration plates in Greece use the /CheckGreece endpoint and return the following information:
- Make / Model
- Age
- Doors
- Engine size
- Representative image
Sample Registration Number:
POT1309
Sample Json:
{
"Description": "KIA Picanto",
"CarMake": {
"CurrentTextValue": "KIA"
},
"CarModel": {
"CurrentTextValue": "Picanto"
},
"MakeDescription": {
"CurrentTextValue": "KIA"
},
"ModelDescription": {
"CurrentTextValue": "Picanto"
},
"Variant": "1.0i 12v Lx",
"VehicleType": "ΕΙΧ",
"Doors": 5,
"EngineBand": 7,
"EngineSize": {
"CurrentTextValue": 999
},
"RegistrationDate": "01/07/2008",
"Region": "Dodecanese - Rhodes",
"ImageUrl": "http://www.πινακιδα.gr/image.aspx/@S0lBIFBpY2FudG8="
}Remove #AWS Credentials cached by #AWSToolkit

This issue affects Windows users, specifically Visual Studio with the AWS Toolkit installed, and it happens when the AWS Toolkit keeps a copy of old AWS credentials that may no longer be valid.
Here is the scenario.
I set up my AWS credentials using AWS configure, this stores the credentials in a file /user/.aws/credentials – I run Visual Studio, and AWS Toolkit keeps a copy of the credentials. Now, I decide to change the AWS credentials, and using the CLI again, I change the credentials on my machine. The CLI works fine, but Visual Studio is using old credentials, and breaks with an error like;
UnrecognizedClientException – The security token included in the request is invalid
at Amazon.Runtime.Internal.HttpErrorResponseExceptionHandler.HandleException(IExecutionContext executionContext, HttpErrorResponseException exception)
at Amazon.Runtime.Internal.ExceptionHandler`1.Handle(IExecutionContext executionContext, Exception exception)
at Amazon.Runtime.Internal.ErrorHandler.ProcessException(IExecutionContext executionContext, Exception exception)
at Amazon.Runtime.Internal.ErrorHandler.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.CallbackHandler.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.EndpointDiscoveryHandler.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.EndpointDiscoveryHandler.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.CredentialsRetriever.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.RetryHandler.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.RetryHandler.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.CallbackHandler.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.CallbackHandler.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.ErrorCallbackHandler.InvokeAsync[T](IExecutionContext executionContext)
at Amazon.Runtime.Internal.MetricsHandler.InvokeAsync[T](IExecutionContext executionContext)
Well, what how to clear the AWSToolkit cache?
Go to
C:\Users\<your user>\AppData\Local\AWSToolkit
and
erase RegisteredAccounts.json
Then restart Visual Studio, and it will find the correct credentials.
Alternative to rotating proxies using #AWS API Gateway and #FireProx

There are many services out there, that can give you a rotating proxy service, using a pool of IP addresses, and some of those pools are probably huge. However, here is an interesting approach discovered by Black Hills Information Security that can use AWS API Gateway as a proxy – A proxy that can only be used for one domain, but it rotates the Egress IP address with every request, and you’re using the IP address pool of an entire AWS Availability zone, and technically, you could set up multiple region end points, if you wanted.
So, the solution is called FireProx, and it’s a Python script that sets up an API gateway for you, such that you can make a request to the AWS gateway URL, and the request will be proxied to the destination,
For example;
https://3eqe4t8sxh.execute-api.eu-west-1.amazonaws.com/fireprox/
Goes to “http://icanhazip.com” – and nearly demonstrates the rotating proxy IP.
To run it, in Windows (Assuming you have Python and VirtualEnv already installed, and AWS already configured):
git clone https://github.com/ustayready/fireprox
cd fireprox
py -m virtualenv -p python3 .
env\Scripts\activate
pip install -r requirements.txt
python fire.pyThen you can create an api gateway using;
python fire.py --command create --url http://icanhazip.com
The GitHub repo is here; so you can verify the source yourself; https://github.com/ustayready/fireprox
