Archive
User Registration Form .com – A #Javascript library to handle user registration and login.

Every website nowadays has a login and register page, and as a developer this boilerplate code takes up time, and gets little credit. Using this JavaScript library, you can manage users, and associate data with your users that will be persisted remotely, all without any server-side coding. It’s secure, fast, and simple to use – and above all it’s free.
User Registration Form.com is a JavaScript library that you can drop into a page that will perform basic user login / registration and allow you store data to associate with that user. It also has a password reset functionality, to allow your users reset their password if they forget it.
Quick Start
Include a reference to our JS library in the head of your page:
<script src="https://userregistrationform.com/user.js"></script>
To handle a new user registration, use this code
user.apiKey = "1A6F4B67DB0937D50386054DE40AA767";
user.email = "you@company.com";
user.password = "a-strong-password";
user.register().then(() => {
// This happens after a successful login
location.href = "Dashboard.html#" + user.id;
}).catch(() => {
// This happens if the registration fails.
alert("register failed");
});To handle a user login, use this code:
user.apiKey = "1A6F4B67DB0937D50386054DE40AA767";
user.email = "you@company.com";
user.password = "a-strong-password";
user.login().then(() => {
// This happens after a successful login
location.href = "Dashboard.html#" + user.id;
}).catch(() => {
// This happens if the login fails
alert("login failed");
});You can also perform a user login using the user id alone, as follows:
user.apiKey = "1A6F4B67DB0937D50386054DE40AA767";
user.id = "{user id here}";
user.login().then(() => {
// user is now logged in
}).catch(() => {
alert("Login failed");
});Once logged in you can store data pertaining to the user by setting the “data” property as follows:
user.data = "Anything";
Although persisting data for a user is fast, it’s not instant, so you shouldn’t navigate away from the page until the data is saved, you can check for this by using the code;
user.data = "Anything";
user.onSetData = () => {
// Safe to leave the page now.
};Please be aware that if you intend to store personally identifiable information in the data field, you must comply with GDPR. You must let your users know that their data is being stored with Infinite Loop Development Ltd, and your users must give informed consent for this. Your data will be deleted if you do not follow GDPR guidelines.
FAQs:
Add Email verification
If you need your users to verify their email address before having full access to your system, then you can do this in conjunction with an email library such as SMTPJS.COM
The flow would be as follows;
- User Registers
- After registration, an email is sent with a link containing the user.id
- On visiting this url, your page sets user.data to “verified” and then to the dashboard
- User Logs in
- If the user.data is not set to “verified”, then access is denied, otherwise the user is sent to the dashboard.
Add a password reset
There is no way to recover a lost password, but you can ask a user to reset his/her own password. You will need a means to send email, and we recommend SMTPJS.COM for this.
The flow would be as follows;
- User requests a password reset
- An email is sent to the email address of the user with a link to a password reset page.
- On the password reset page, the following code is executed;
async function reset() {
user.apiKey = "1A6F4B67DB0937D50386054DE40AA767";
user.email = "you@company.com";
user.password = "new-password";
try {
await user.resetPassword();
alert("password reset ok");
} catch (e) {
alert("password reset failed");
}
}
List all users
On an admin page of your website, you can list all the users of under your account, by calling the following code:
async function list() {
user.apiKey = "1A6F4B67DB0937D50386054DE40AA767";
user.password = "**root password here**";
try {
var list = await user.list();
alert(JSON.stringify(list));
} catch (e) {
alert("list failed");
}
}
Since your root password is visible on this page, you should make sure that your admin page is not accessible to unauthorized visitors. The user list returned will contain all user ids, user email, and user data. If needed, you can assume the identity of one of your users by using the user id provided in the return data.
Connect a user with Shopping cart, CMS system, product X
This system is designed to be flexible enough, such that you can store any data you need regarding a user (up to 8Kb of data). Instead of storing plain text, like the examples above, you can also store JSON, so that you can represent a Shopping basket of products, or a rich CMS user profile with name, address and contact details. The user ID is always represented by a GUID (Genuinely unique Identifier), so it is statistically impossible for there to be an overlap between the ID returned by User.js and any other system. Although we’re unlikely to be able to offer free advice on how to connect this system to your Product X, it’s beyond the remit of our support for this free software. If you would like to sponsor the development of a feature, please contact us.
Asynchronous Pre-Request script in #Postman

A Pre-request script in Postman allows you to dynamically change the request body based on any JavaScript function you provide, this sometimes is done to dynamically calculate HMACs in the request, such that you don’t have to manually calculate it before every request.
However, it’s not obvious how to create an asynchronous pre-request script, that is one that does not return instantly, but has to wait for some external factor (i.e. a HTTP Request), before completing the main request.
Here is the simple example, where we want to inject the user’s IP address into the HTTP request body before sending; as follows –
new Promise(resolve =>
pm.sendRequest("http://checkip.amazonaws.com/",function(e, r){
pm.request.body.update(JSON.stringify(r.text()));
resolve();
})
);And, the main request will not execute until the promise returned in the pre-request script is resolved.
Firewall rules to allow internal connection to #AWS Elastic IP

This is probably a very specific problem, that I’m not sure that many people will have, but I’ll share the problem and solution here, since it’s not very obvious.
Given a piece of software, with a config file containing a DSN. I want the DSN to be the same on Dev as on Production, so that there are no “Works on my machine” errors.
My server on AWS has an Elastic IP, and a windows firewall to permit remote access to limited IP addresses to the Database port.
On Dev, we point the DSN to the Elastic IP, and all is good. On Prod, the same Elastic IP times out. — help!!
SQLCMD LOCALHOST -> Works
SQLCMD PRIVATE IP -> Works
SQLCMD ELASTIC IP -> Times out (only on same machine)
Obviously “LOCALHOST” and “PRIVATE IP” are not going to work from DEV.
So, the solution; Add the ELASTIC IP into the Scope on the Firewall !!
Comparing #OCR services on #handwritten text.
| 1 | Filename | Image | Tesseract | OCR.SPACE | Azure | IRON OCR | AWS Texttract | AWS Textract (DDT) | |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 1457617912-CROP.jpg | 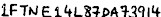 | 1FTME1HL84DA439N | 1FTNELGLRDATNG | 1FT 4L87DA73914 | 1FT4L87DA73914 | |||
| 3 | 1457617924-CROP.jpg |  | MGPWUEWLML | DLEPLLL1R29LDSL | LD4GP4412R296096 | LD4GP4412R296096 | |||
| 4 | 1457638629-CROP.jpg |  | 2STME20U071MEM | JTNCR2000776480GL | |||||
| 5 | 1457643042-CROP.jpg |  | 5H63H5H8SFHTFM | SHEKHSHESTMTHY | BHGGKSH85FM7499 | BHGGKSH85FM7499 | |||
| 6 | 1457670471-CROP.jpg | 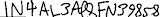 | JNFML3WFNSWSS3 | IN4 | IN4. | ||||
| 7 | 1457670537-CROP.jpg |  | LNEPALBAPEMWM | ()VE-IV 1 | ANDPALZAPLENZFRST | LNPAL3, | LNPAL3, | ||
| 8 | 1457677623-CROP.jpg | 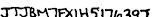 | TUBM1FXMGW1AG1 | TTRMEX1WUS1720S | JTJBMTEXIH5176297 | JTJBMTEXIH5176297 | |||
| 9 | 1457677635-CROP.jpg |  | MJHSHGB91 | JTTTRMTEXHES17963932 | JTJ8M7FX1H5176397 | JTJ8M7FX1H5176397 | |||
| 10 | 1457734011-CROP.jpg | 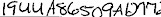 | FWHATSGSGCMDWW | 9UUASCSATATL | 1944A86509ALY7 | 1944A86509ALY7 | |||
| 11 | EASY-CROP.jpg |  | WAUDH74F16N117113 | WAUDH74F16N117113 | WAUDH74F16N117113 | WAUDH74F16N117113 | WAUDH74F16N117113 | WAUDH74F16N117113 |
Given 10 images, 9 containing handwritten text, 1 containing printed text, I ran these through five different OCR services to compare accuracy. Each one could correctly interpret the printed text, but the handwritten text was not accurately recognised by any service, except for AWS Textract.
There were a few “didn’t run” contenders, because I couldn’t get their API to work in the time I allotted myself (one hour). Which were FileStack, Mindee, and Google Cloud Vision. These may have returned better results but the APIs were too convolute to run a simple test.
First up is Tesseract, which was some software running locally, with the following additional parameters,
-psm 8 -c tessedit_char_whitelist=ABCDEFGHJKLMNPRSTUVWXYZ0123456789
What does this mean. Well – the text are handwritten VIN numbers, which do not include the letters O, I and Q because these are too similar to numbers, and the text was in uppercase, and one word.
Tesseract made a good attempt, and fared very well against commercial offerings, but in effect, it was wrong on each example apart from the printed text.
OCR.SPACE is a free OCR API, and was easy to get started with; You should get your own API key, but this key is free, so I don’t care if it’s public
private static string OcrSpace(string imageFileLocation)
{
var postData = "apikey=b8fd788a8b88957";
postData += "&url=" + HttpUtility.UrlEncode(imageFileLocation);
const string strUrl = "https://api.ocr.space/parse/image";
var web = new WebClient();
web.Headers.Add(HttpRequestHeader.ContentType, "application/x-www-form-urlencoded");
var json = "";
try
{
json = web.UploadString(strUrl, postData);
}
catch (WebException ex)
{
var resp = new StreamReader(ex.Response.GetResponseStream()).ReadToEnd();
Console.WriteLine(resp);
}
var jParsed = JObject.Parse(json);
var result = jParsed["ParsedResults"].FirstOrDefault();
return result["ParsedText"] + "";
}This code takes in an image URL and returns text – very simple, but it returns an empty string when it fails to recognise, so it was one of the worst performers.
Microsoft Azure computer vision was pretty useless too with handwritten text. Returning either nothing or complete garbage. Although it was very fast.
private static string Azure(string imageFileLocation)
{
const string strUrl = "https://westeurope.api.cognitive.microsoft.com/vision/v1.0/ocr?language=unk&detectOrientation=true";
var wc = new WebClient();
wc.Headers["Ocp-Apim-Subscription-Key"] = "**REDACTED**";
var jPost = new { url = imageFileLocation };
var post = JsonConvert.SerializeObject(jPost, Formatting.Indented);
var json = wc.UploadString(strUrl, "POST", post);
var jObject = JObject.Parse(json);
var output = "";
foreach (var region in jObject["regions"])
{
foreach (var line in region["lines"])
{
foreach (var word in line["words"])
{
output += word["text"] + " ";
}
output += Environment.NewLine;
}
}
return output.Trim();
}IRON OCR is also based on tesseract, and preformed similarly to the local Tesseract version. Very easy to use, but comes with a price tag. Not having to upload the image to temporary storage is a plus.
private static string ironOCR(string filename)
{
var engine = new IronTesseract
{
Configuration =
{
WhiteListCharacters = "ABCDEFGHJKLMNPRSTUVWXYZ0123456789",
}
};
var Result = engine.Read(filename).Text;
return Result;
}The winning service that I tried was AWS textract, and I tested it using their online demo:
https://eu-west-1.console.aws.amazon.com/textract/home?region=eu-west-1#/demo
Here is the equivalent code;
private static string Textract(string filename)
{
var readFile = File.ReadAllBytes(filename);
var stream = new MemoryStream(readFile);
var client = new AmazonTextractClient();
var ddtRequest = new DetectDocumentTextRequest
{
Document = new Document
{
Bytes = stream
}
};
var detectDocumentTextResponse = client.DetectDocumentText(ddtRequest);
var words = detectDocumentTextResponse.Blocks
.Where(b => b.BlockType == BlockType.WORD)
.Select(b => b.Text)
.ToArray();
var result = string.Join("", words);
return result;
}