Comparing #OCR services on #handwritten text.
| 1 | Filename | Image | Tesseract | OCR.SPACE | Azure | IRON OCR | AWS Texttract | AWS Textract (DDT) | |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 1457617912-CROP.jpg | 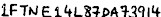 | 1FTME1HL84DA439N | 1FTNELGLRDATNG | 1FT 4L87DA73914 | 1FT4L87DA73914 | |||
| 3 | 1457617924-CROP.jpg |  | MGPWUEWLML | DLEPLLL1R29LDSL | LD4GP4412R296096 | LD4GP4412R296096 | |||
| 4 | 1457638629-CROP.jpg |  | 2STME20U071MEM | JTNCR2000776480GL | |||||
| 5 | 1457643042-CROP.jpg |  | 5H63H5H8SFHTFM | SHEKHSHESTMTHY | BHGGKSH85FM7499 | BHGGKSH85FM7499 | |||
| 6 | 1457670471-CROP.jpg | 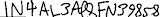 | JNFML3WFNSWSS3 | IN4 | IN4. | ||||
| 7 | 1457670537-CROP.jpg |  | LNEPALBAPEMWM | ()VE-IV 1 | ANDPALZAPLENZFRST | LNPAL3, | LNPAL3, | ||
| 8 | 1457677623-CROP.jpg | 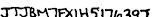 | TUBM1FXMGW1AG1 | TTRMEX1WUS1720S | JTJBMTEXIH5176297 | JTJBMTEXIH5176297 | |||
| 9 | 1457677635-CROP.jpg |  | MJHSHGB91 | JTTTRMTEXHES17963932 | JTJ8M7FX1H5176397 | JTJ8M7FX1H5176397 | |||
| 10 | 1457734011-CROP.jpg | 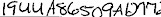 | FWHATSGSGCMDWW | 9UUASCSATATL | 1944A86509ALY7 | 1944A86509ALY7 | |||
| 11 | EASY-CROP.jpg |  | WAUDH74F16N117113 | WAUDH74F16N117113 | WAUDH74F16N117113 | WAUDH74F16N117113 | WAUDH74F16N117113 | WAUDH74F16N117113 |
Given 10 images, 9 containing handwritten text, 1 containing printed text, I ran these through five different OCR services to compare accuracy. Each one could correctly interpret the printed text, but the handwritten text was not accurately recognised by any service, except for AWS Textract.
There were a few “didn’t run” contenders, because I couldn’t get their API to work in the time I allotted myself (one hour). Which were FileStack, Mindee, and Google Cloud Vision. These may have returned better results but the APIs were too convolute to run a simple test.
First up is Tesseract, which was some software running locally, with the following additional parameters,
-psm 8 -c tessedit_char_whitelist=ABCDEFGHJKLMNPRSTUVWXYZ0123456789
What does this mean. Well – the text are handwritten VIN numbers, which do not include the letters O, I and Q because these are too similar to numbers, and the text was in uppercase, and one word.
Tesseract made a good attempt, and fared very well against commercial offerings, but in effect, it was wrong on each example apart from the printed text.
OCR.SPACE is a free OCR API, and was easy to get started with; You should get your own API key, but this key is free, so I don’t care if it’s public
private static string OcrSpace(string imageFileLocation)
{
var postData = "apikey=b8fd788a8b88957";
postData += "&url=" + HttpUtility.UrlEncode(imageFileLocation);
const string strUrl = "https://api.ocr.space/parse/image";
var web = new WebClient();
web.Headers.Add(HttpRequestHeader.ContentType, "application/x-www-form-urlencoded");
var json = "";
try
{
json = web.UploadString(strUrl, postData);
}
catch (WebException ex)
{
var resp = new StreamReader(ex.Response.GetResponseStream()).ReadToEnd();
Console.WriteLine(resp);
}
var jParsed = JObject.Parse(json);
var result = jParsed["ParsedResults"].FirstOrDefault();
return result["ParsedText"] + "";
}This code takes in an image URL and returns text – very simple, but it returns an empty string when it fails to recognise, so it was one of the worst performers.
Microsoft Azure computer vision was pretty useless too with handwritten text. Returning either nothing or complete garbage. Although it was very fast.
private static string Azure(string imageFileLocation)
{
const string strUrl = "https://westeurope.api.cognitive.microsoft.com/vision/v1.0/ocr?language=unk&detectOrientation=true";
var wc = new WebClient();
wc.Headers["Ocp-Apim-Subscription-Key"] = "**REDACTED**";
var jPost = new { url = imageFileLocation };
var post = JsonConvert.SerializeObject(jPost, Formatting.Indented);
var json = wc.UploadString(strUrl, "POST", post);
var jObject = JObject.Parse(json);
var output = "";
foreach (var region in jObject["regions"])
{
foreach (var line in region["lines"])
{
foreach (var word in line["words"])
{
output += word["text"] + " ";
}
output += Environment.NewLine;
}
}
return output.Trim();
}IRON OCR is also based on tesseract, and preformed similarly to the local Tesseract version. Very easy to use, but comes with a price tag. Not having to upload the image to temporary storage is a plus.
private static string ironOCR(string filename)
{
var engine = new IronTesseract
{
Configuration =
{
WhiteListCharacters = "ABCDEFGHJKLMNPRSTUVWXYZ0123456789",
}
};
var Result = engine.Read(filename).Text;
return Result;
}The winning service that I tried was AWS textract, and I tested it using their online demo:
https://eu-west-1.console.aws.amazon.com/textract/home?region=eu-west-1#/demo
Here is the equivalent code;
private static string Textract(string filename)
{
var readFile = File.ReadAllBytes(filename);
var stream = new MemoryStream(readFile);
var client = new AmazonTextractClient();
var ddtRequest = new DetectDocumentTextRequest
{
Document = new Document
{
Bytes = stream
}
};
var detectDocumentTextResponse = client.DetectDocumentText(ddtRequest);
var words = detectDocumentTextResponse.Blocks
.Where(b => b.BlockType == BlockType.WORD)
.Select(b => b.Text)
.ToArray();
var result = string.Join("", words);
return result;
}